MoBA:Moonshot AI 提出的新型注意力機(jī)制,高效處理長文本的革命性技術(shù)
在人工智能領(lǐng)域,注意力機(jī)制一直是大型語言模型(LLMs)的核心技術(shù)之一。然而,隨著模型規(guī)模的不斷擴(kuò)大和應(yīng)用場景的日益復(fù)雜,傳統(tǒng)的注意力機(jī)制在處理長上下文任務(wù)時(shí)逐漸暴露出計(jì)算效率低、資源消耗大的問題。為了突破這一瓶頸,Moonshot AI 推出了 MoBA(Mixture of Block Attention),一種全新的注意力機(jī)制,旨在提高長文本處理的效率,同時(shí)保持與全注意力機(jī)制相當(dāng)?shù)男阅堋?br />本文將詳細(xì)介紹 MoBA 的核心功能、技術(shù)原理、應(yīng)用場景以及其在 AI 領(lǐng)域的潛力,幫助您全面了解這一創(chuàng)新技術(shù)。
MoBA 是什么?
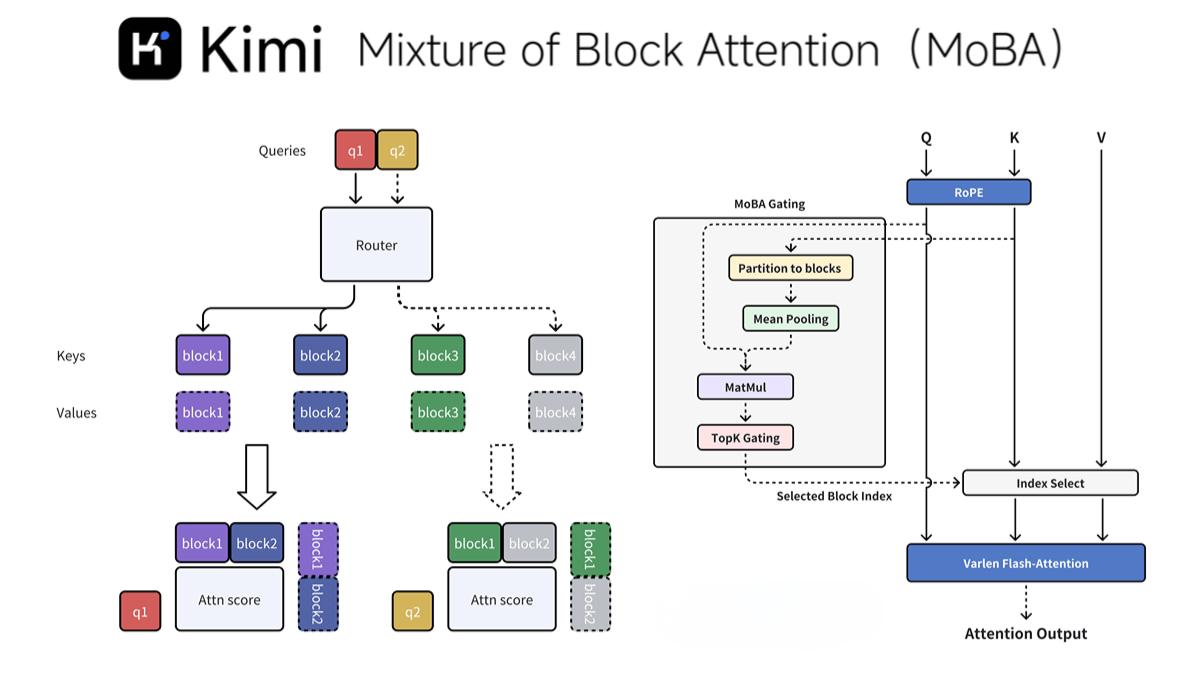
MoBA(Mixture of Block Attention)是一種由 Moonshot AI 提出的新型注意力機(jī)制,專為提高大型語言模型處理長上下文任務(wù)的效率而設(shè)計(jì)。通過將上下文劃分為多個(gè)塊(block),并引入無參數(shù)的 top-k 門控機(jī)制,MoBA 允許每個(gè)查詢 token 動(dòng)態(tài)選擇最相關(guān)的鍵值(KV)塊進(jìn)行注意力計(jì)算,從而顯著降低了計(jì)算復(fù)雜度。
MoBA 的核心優(yōu)勢在于其靈活性和高效性:
-
無縫切換注意力模式:MoBA 可以在全注意力和稀疏注意力模式之間無縫切換,既保留了全注意力機(jī)制的性能,又大幅提高了計(jì)算效率。
-
少結(jié)構(gòu)原則:MoBA 避免引入預(yù)定義的偏見,讓模型自主決定關(guān)注點(diǎn),確保了模型的靈活性和適應(yīng)性。
-
高性能實(shí)現(xiàn):MoBA 結(jié)合了 FlashAttention 和 MoE(混合專家模型)的優(yōu)化技術(shù),在處理 1M token 的長文本時(shí),速度比傳統(tǒng)全注意力機(jī)制快 6.5 倍,而在處理 10M token 時(shí),速度提升可達(dá) 16 倍。
MoBA 已經(jīng)在 Kimi 平臺(tái)上得到實(shí)際驗(yàn)證,并且開源了相關(guān)代碼,為開發(fā)者提供了便捷的集成方式。
MoBA 的主要功能
MoBA 的設(shè)計(jì)圍繞以下幾個(gè)核心功能展開,使其成為處理長文本任務(wù)的理想選擇:
1. 塊稀疏注意力
MoBA 將上下文劃分為多個(gè)塊(block),并讓每個(gè)查詢 token 動(dòng)態(tài)選擇最相關(guān)的鍵值(KV)塊進(jìn)行注意力計(jì)算。這種塊劃分策略不僅提高了計(jì)算效率,還確保了模型能夠關(guān)注到最關(guān)鍵的信息。
2. 無參數(shù)門控機(jī)制
MoBA 引入了一種新穎的 top-k 門控機(jī)制,為每個(gè)查詢 token 動(dòng)態(tài)選擇最相關(guān)的塊。這種機(jī)制無需額外的參數(shù)訓(xùn)練,確保了模型的輕量化和高效性。
3. 全注意力與稀疏注意力的無縫切換
MoBA 的設(shè)計(jì)使其能夠靈活地在全注意力和稀疏注意力模式之間切換,既保留了全注意力機(jī)制的性能,又大幅提高了計(jì)算效率。
4. 高性能實(shí)現(xiàn)
MoBA 結(jié)合了 FlashAttention 和 MoE(混合專家模型)的優(yōu)化技術(shù),顯著降低了計(jì)算復(fù)雜度。實(shí)驗(yàn)表明,MoBA 在處理 1M token 的長文本時(shí),速度比傳統(tǒng)全注意力機(jī)制快 6.5 倍,而在處理 10M token 時(shí),速度提升可達(dá) 16 倍。
5. 與現(xiàn)有模型的兼容性
MoBA 可以輕松集成到現(xiàn)有的 Transformer 模型中,無需進(jìn)行大量訓(xùn)練調(diào)整,為開發(fā)者提供了便捷的遷移路徑。
MoBA 的技術(shù)原理
MoBA 的技術(shù)原理使其在長文本處理任務(wù)中表現(xiàn)出色:
1. 因果性設(shè)計(jì)
為了保持自回歸語言模型的因果關(guān)系,MoBA 確保查詢 token 不能關(guān)注未來的塊,在當(dāng)前塊中應(yīng)用因果掩碼。這種設(shè)計(jì)避免了信息泄露,同時(shí)保留了局部上下文信息。
2. 細(xì)粒度塊劃分與擴(kuò)展性
MoBA 支持細(xì)粒度的塊劃分,類似于 MoE(混合專家模型)中的專家劃分策略。這種設(shè)計(jì)提升了性能,使 MoBA 能夠擴(kuò)展到極長的上下文(如 10M token),在長上下文任務(wù)中表現(xiàn)出色。
MoBA 的應(yīng)用場景
MoBA 的高效性和靈活性使其在多個(gè)領(lǐng)域具有廣泛的應(yīng)用潛力:
1. 長文本處理
MoBA 通過塊劃分和動(dòng)態(tài)選擇機(jī)制,顯著降低了長文本處理的計(jì)算復(fù)雜度,適用于歷史數(shù)據(jù)分析、復(fù)雜推理和決策等任務(wù)。
2. 長上下文語言模型
MoBA 已經(jīng)被部署在 Kimi 平臺(tái)上,顯著提升了長上下文請求的處理效率。在處理 1M 或 10M token 的超長文本時(shí),速度分別提升了 6.5 倍和 16 倍。
3. 多模態(tài)任務(wù)
MoBA 的架構(gòu)可以擴(kuò)展到多模態(tài)任務(wù)中,處理和理解多種類型的數(shù)據(jù)(如文本和圖像),為復(fù)雜任務(wù)提供支持。
4. 個(gè)人助理與智能家居
在個(gè)人助理和智能家居控制中,MoBA 可以高效處理用戶的長指令,通過動(dòng)態(tài)注意力機(jī)制快速響應(yīng),提升用戶體驗(yàn)。
5. 教育與學(xué)習(xí)
MoBA 可以幫助學(xué)生處理長篇學(xué)習(xí)資料,輔助完成作業(yè),或提供基于長上下文的智能輔導(dǎo)。
6. 復(fù)雜推理與決策
MoBA 的動(dòng)態(tài)注意力機(jī)制能夠高效處理復(fù)雜的推理任務(wù),如長鏈推理(CoT)和多步?jīng)Q策,同時(shí)保持與全注意力機(jī)制相當(dāng)?shù)男阅堋?/p>
MoBA 的項(xiàng)目地址
如果您對 MoBA 感興趣,可以通過以下鏈接了解更多:
-
Github 倉庫:https://github.com/MoonshotAI/MoBA
-
技術(shù)論文:https://github.com/MoonshotAI/MoBA
總結(jié)
MoBA 是 Moonshot AI 推出的革命性注意力機(jī)制,通過塊劃分和動(dòng)態(tài)選擇機(jī)制,顯著提高了大型語言模型處理長文本的效率。其靈活的注意力模式切換、高性能實(shí)現(xiàn)以及與現(xiàn)有模型的兼容性,使其在多個(gè)領(lǐng)域具有廣泛的應(yīng)用潛力。無論是學(xué)術(shù)研究還是工業(yè)應(yīng)用,MoBA 都為長文本處理任務(wù)提供了全新的解決方案。
如果您正在尋找一種高效、靈活的注意力機(jī)制,MoBA 絕對是一個(gè)值得探索的選擇。