LLaVA-OneVision – 字節(jié)跳動(dòng)推出的開源多模態(tài)AI模型
LLaVA-OneVision是什么
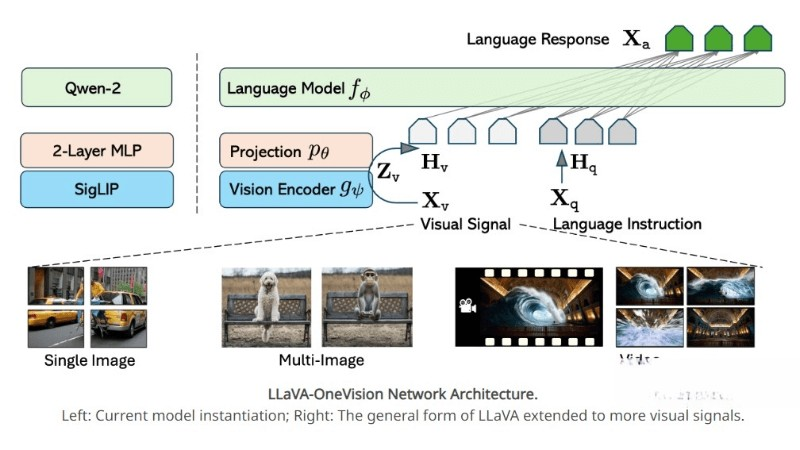
LLaVA-OneVision是字節(jié)跳動(dòng)推出開源的多模態(tài)AI模型,LLaVA-OneVision通過整合數(shù)據(jù)、模型和視覺表示的見解,能同時(shí)處理單圖像、多圖像和視頻場(chǎng)景下的計(jì)算機(jī)視覺任務(wù)。LLaVA-OneVision支持跨模態(tài)/場(chǎng)景的遷移學(xué)習(xí),特別在圖像到視頻的任務(wù)轉(zhuǎn)移中表現(xiàn)出色,具有強(qiáng)大的視頻理解和跨場(chǎng)景能力。
LLaVA-OneVision的主要功能
- 多模態(tài)理解:能理解和處理單圖像、多圖像和視頻內(nèi)容,提供深入的視覺分析。
- 任務(wù)遷移:支持不同視覺任務(wù)之間的遷移學(xué)習(xí),尤其是圖像到視頻的任務(wù)遷移,展現(xiàn)出視頻理解能力。
- 跨場(chǎng)景能力:在不同的視覺場(chǎng)景中展現(xiàn)出強(qiáng)大的適應(yīng)性和性能,包括但不限于圖像分類、識(shí)別和描述生成。
- 開源貢獻(xiàn):模型的開源性質(zhì)為社區(qū)提供了代碼庫(kù)、預(yù)訓(xùn)練權(quán)重和多模態(tài)指令數(shù)據(jù),促進(jìn)了研究和應(yīng)用開發(fā)。
- 高性能:在多個(gè)基準(zhǔn)測(cè)試中超越了現(xiàn)有模型,顯示出卓越的性能和泛化能力。
LLaVA-OneVision的技術(shù)原理
- 多模態(tài)架構(gòu):模型采用多模態(tài)架構(gòu),將視覺信息和語(yǔ)言信息融合,以理解和處理不同類型的數(shù)據(jù)。
- 語(yǔ)言模型集成:選用了Qwen-2作為語(yǔ)言模型,模型具備強(qiáng)大的語(yǔ)言理解和生成能力,能準(zhǔn)確理解用戶輸入并生成高質(zhì)量文本。
- 視覺編碼器:使用Siglip作為視覺編碼器,在圖像和視頻特征提取方面表現(xiàn)出色,能捕捉關(guān)鍵信息。
- 特征映射:通過多層感知機(jī)(MLP)將視覺特征映射到語(yǔ)言嵌入空間,形成視覺標(biāo)記,為多模態(tài)融合提供橋梁。
- 任務(wù)遷移學(xué)習(xí):允許在不同模態(tài)或場(chǎng)景之間進(jìn)行任務(wù)遷移,通過這種遷移學(xué)習(xí),模型能發(fā)展出新的能力和應(yīng)用。
LLaVA-OneVision的項(xiàng)目地址
- GitHub倉(cāng)庫(kù):https://llava-vl.github.io/blog/2024-08-05-llava-onevision/
- arXiv技術(shù)論文:https://arxiv.org/pdf/2408.03326
如何使用LLaVA-OneVision
- 環(huán)境準(zhǔn)備:確保有合適的計(jì)算環(huán)境,包括硬件資源和必要的軟件依賴。
- 獲取模型:訪問LLaVA-OneVision的Github倉(cāng)庫(kù),下載或克隆模型的代碼庫(kù)和預(yù)訓(xùn)練權(quán)重。
- 安裝依賴:根據(jù)項(xiàng)目文檔安裝所需的依賴庫(kù),如深度學(xué)習(xí)框架(例如PyTorch或TensorFlow)和其他相關(guān)庫(kù)。
- 數(shù)據(jù)準(zhǔn)備:準(zhǔn)備或獲取想要模型處理的數(shù)據(jù),可能包括圖像、視頻或多模態(tài)數(shù)據(jù),并按照模型要求格式化數(shù)據(jù)。
- 模型配置:根據(jù)具體應(yīng)用場(chǎng)景配置模型參數(shù),涉及到調(diào)整模型的輸入輸出格式、學(xué)習(xí)率等超參數(shù)。
LLaVA-OneVision的應(yīng)用場(chǎng)景
- 圖像和視頻分析:對(duì)圖像和視頻內(nèi)容進(jìn)行深入分析,包括物體識(shí)別、場(chǎng)景理解、圖像描述生成等。
- 內(nèi)容創(chuàng)作輔助:為藝術(shù)家和創(chuàng)作者提供靈感和素材,幫助創(chuàng)作圖像、視頻等多媒體內(nèi)容。
- 聊天機(jī)器人:作為聊天機(jī)器人,與用戶進(jìn)行自然流暢的對(duì)話,提供信息查詢、娛樂交流等服務(wù)。
- 教育和培訓(xùn):在教育領(lǐng)域,輔助教學(xué)過程,提供視覺輔助材料,增強(qiáng)學(xué)習(xí)體驗(yàn)。
- 安全監(jiān)控:在安全領(lǐng)域,分析監(jiān)控視頻,識(shí)別異常行為或事件,提高安全監(jiān)控的效率。
? 版權(quán)聲明
本站文章版權(quán)歸奇想AI導(dǎo)航網(wǎng)所有,未經(jīng)允許禁止任何形式的轉(zhuǎn)載。
相關(guān)文章



















奇想AI導(dǎo)航網(wǎng)收錄了國(guó)內(nèi)外數(shù)百個(gè)不同類型的AI工具,每日更新和添加最新AI工具,奇想AI導(dǎo)航網(wǎng)還推薦了AI學(xué)習(xí)開發(fā)的常用網(wǎng)站、框架和模型,幫助你加入人工智能浪潮,自動(dòng)化高效完成任務(wù)!
Ctrl + D 或 ? + D 收藏本站到瀏覽器書簽欄。